Lab 4 Classification
Overview
While it is possible for a human to look at a satellite image and identify objects or land cover types based on their visual characteristics, the sheer magnitude and volume of imagery makes it very difficult to do this manually. To compensate, machine learning allows computers to process this information much quicker than a human and find meaningful insights about what we see in the imagery. Image classification is an essential component in today’s remote sensing, and there are many opportunities in this growing field. By training ML models to efficiently process the data and return labeled information, we can focus on the insights and higher-level insights.
Google Earth Engine offers many options in to work with classification which we will get familiar with. Most broadly, we can separate classification into two parts - supervised and unsupervised classification. We will introduce both components and work our way through several examples.
4.1 Introduction to Classification
For present purposes, define prediction as guessing the value of some geographic variable of interest g, using a function G that takes as input a pixel vector p:
\[ G_{t}(p_{i}) = g_{i} \] The i in this equation refers to a particular instance from a set of pixels. Think of G as a guessing function and \(g_{i}\) as the guess for pixel i. The T in the subscript of G refers to a training set (a set of known values for p and the correct g), used to infer the structure of G. You have to choose a suitable G to train with T.
When g is nominal, or a fixed category (ex., {‘water’, ‘vegetation’, ‘bare’}), we call this classification.
When g is numeric (ex., {0, 1, 2, 3}), we call this regression.
This is an incredibly simplistic description of a problem addressed in a broad range of fields including mathematics, statistics, data mining, machine learning. For our purposes, we will go through some examples using these concepts in Google Earth Engine and then provide more resources for further reading at the end.
4.2 Unsupervised Classification
Unsupervised classification finds unique groupings in the dataset without manually developed training data. The computer will cycle through the pixels, look at the characteristics of the different bands, and pixel-by-pixel begin to group information together. Perhaps pixels with a blue hue and a low NIR value are grouped together, while green-dominant pixels are also grouped together. The outcome of unsupervised classification is that each pixel is categorized within the context of the image, and there will be the number of categories specified. One important note, is that the number of clusters is set by the user, and this plays a major role in how the algorithm operates. Too many clusters creates unnecessary noise, while too few clusters does not have enough granularity.
Google Earth Engine provides documentation on working with unsupervised classification within their ecosystem, and we will be focusing on the ee.Clusterer package, which provides a flexible unsupervised classification (or clustering) in an easy-to-use way.
Clusterers are used in the same manner as classifiers in Earth Engine. The general workflow for clustering is:
- Assemble features with numeric properties to find clusters
- Instantiate a clusterer - set its parameters if necessary
- Train the clusterer using the training data
- Apply the clusterer to an image or feature collection
- Label the clusters
Begin by creating a study region - in this case we will be working the Amazon Rainforest.
// Lab: Unsupervised Classification (Clustering)
// Create region
var region = ee.Geometry.Polygon([[
[-54.07419968695418, -3.558053010380929],
[-54.07419968695418, -3.8321399733300234],
[-53.14310837836043, -3.8321399733300234],
[-53.14310837836043, -3.558053010380929]]], null, false);
Map.addLayer(region, {}, "Region");
Map.centerObject(region, 10);// Function to mask clouds based on the pixel_qa band of Landsat 8 SR data.
function maskL8sr(image) {
// Bits 3 and 5 are cloud shadow and cloud, respectively.
var cloudShadowBitMask = (1 << 3);
var cloudsBitMask = (1 << 5);
// Get the pixel QA band.
var qa = image.select('pixel_qa');
// Both flags should be set to zero, indicating clear conditions.
var mask = qa.bitwiseAnd(cloudShadowBitMask).eq(0)
.and(qa.bitwiseAnd(cloudsBitMask).eq(0));
return image.updateMask(mask);
}We will be working with Landsat data, which you can read in below. We will filter the data to the date range, map cloud pixels and work within the study region.
// Load Landsat 8 annual composites.
var landsat = ee.ImageCollection('LANDSAT/LC08/C01/T1_SR')
.filterDate('2019-01-01', '2019-12-31')
.map(maskL8sr)
.filterBounds(region)
.median();
//Display Landsat data
var visParams = {
bands: ['B4', 'B3', 'B2'],
min: 0,
max: 3000,
gamma: 1.4,
};
Map.centerObject(region, 9);
Map.addLayer(landsat, visParams, "Landsat 8 (2016)");In this case, we will randomly select a sample of 5000 pixels in the region to build a clustering model - we will use this ‘training’ data to find clustering groups and then apply it to the rest of the data We will also set the variable clusterNum to idenfity how many categories to use. Start with 15, and modify based on the output and needs of your experiment. Note that we are using ee.Clusterer.wekaKMeans,
// Create a training dataset.
var training = landsat.sample({
region: region,
scale: 30,
numPixels: 5000
});
var clusterNum = 15
// Instantiate the clusterer and train it.
var clusterer = ee.Clusterer.wekaKMeans(clusterNum).train(training);
// Cluster the input using the trained clusterer.
var result = landsat.cluster(clusterer);
print("result", result.getInfo());
// Display the clusters with random colors.
Map.addLayer(result.randomVisualizer(), {}, 'Unsupervised Classification');As you can see from the output, the result is quite vivid. On the ‘layers’ toggle on the top-right of the map section, increase the transparency of the layer to compare it to the satellite imagery.
Change the variable clusterNum and run through some different options to find better results. Note that the output of an unsupervised clustering model is not specifying that each pixel should be a certain type of label (ex, the pixel is ‘water’), but rather that these pixels have similar characteristics.
Question: If you were going to use a clustering model to identify water in the image, is 15 an appropriate cluster number?
4.3 Supervised Classification
Just like in unsupervised classification, GEE has documentation that works through several examples. Supervised classification is an iterative process of obtaining training data, creating an initial model, reviewing the results and tuning the parameters. Many projects using supervised classification may take several months of years of fine-tuning, requiring constant refinement and maintenance. Below is a list of the steps of Supervised learning according to GEE.
- Collect the training data
- Instantiate the classifier
- Train the classifier
- Classify the image
- Tune the model.
We will begin by creating training data manually within GEE. Using the geometry tools and the Landsat composite as a background, we can digitize training polygons. We’ll need to do two things: identify where polygons occur on the ground, and label them with the proper class number.
- Draw a polygon around an area of bare earth (dirt, no vegetation), then configure the import. Import as FeatureCollection, then click
+ New property. Name the new property ‘class’ and give it a value of 0. The dialog should show class: 0. Name the import ‘bare’. + New property> Draw a polygon around vegetation > import as FeatureCollection > add a property > name it ‘class’ and give it a value of 1. Name the import ‘vegetation’.+ New property> Draw a polygon around water > import as FeatureCollection > add a property > name it ‘class’ and give it a value of 2. Name the import ‘water’.- You should have three FeatureCollection imports named ‘bare’, ‘vegetation’ and ‘water’. Merge them into one FeatureCollection:
var trainingFeatures = bare.merge(vegetation).merge(water);In the merged FeatureCollection, each Feature should have a property called ‘class’ where the classes are consecutive integers, one for each class, starting at 0. Verify that this is true.
For Landsat, we will use the following bands for their predictive values - we could just keep the visual bands, but using a larger number of predictive values in many cases improves the model’s ability to find relationships and patterns in the data.
var predictionBands = ['B2', 'B3', 'B4', 'B5', 'B6', 'B7', 'B10', 'B11'];Create a training set T for the classifier by sampling the Landsat composite with the merged features.
var classifierTraining = landsat.select(predictionBands)
.sampleRegions({
collection: trainingFeatures,
properties: ['class'],
scale: 30
});The choice of classifier is not always obvious, but a CART (a decision tree when running in classification mode) is an excellent starting point. Instantiate a CART and train it.
var classifier = ee.Classifier.smileCart().train({
features: classifierTraining,
classProperty: 'class',
inputProperties: predictionBands
});Classify the image and visualize the image.
var classified = landsat.select(predictionBands)
.classify(classifier);
Map.addLayer(classified,
{min: 0, max: 2,
palette: ['red', 'green', 'blue']},
'classified');Inspect the result. Some things to test if the result is unsatisfactory:
- Other classifiers
- Try some of the other classifiers in Earth Engine to see if the result is better or different. You can find different classifiers under
Docson the left panel of the console.
- Try some of the other classifiers in Earth Engine to see if the result is better or different. You can find different classifiers under
- Different (or more) training data.
- Try adjusting the shape and/or size of your training polygons to have a more representative sample of your classes. It is very common to either underfit or overfit your model when beginning the process.
- Add more predictors.
- Try adding spectral indices to the input variables.
4.4 Accuracy Assessment
The previous section asked the question whether the result is satisfactory or not. In remote sensing, the quantification of the answer is called accuracy assessment. In the regression context, a standard measure of accuracy is the Root Mean Square Error (RMSE) or the correlation between known and predicted values. (Although the RMSE is returned by the linear regression reducer, beware: this is computed from the training data and is not a fair estimate of expected prediction error when guessing a pixel not in the training set). It is testing how accurate the model is based on the existing training data, but proper methodology uses separate ground-truth values for testing. In the classification context, accuracy measurements are often derived from a confusion matrix.
The first step is to partition the set of known values into training and testing sets. Reusing the classification training set, add a column of random numbers used to partition the known data where about 60% of the data will be used for training and 40% for testing:
var trainingTesting = classifierTraining.randomColumn();
var trainingSet = trainingTesting.filter(ee.Filter.lessThan('random', 0.6));
var testingSet = trainingTesting.filter(ee.Filter.greaterThanOrEquals('random', 0.6)); Train the classifier with the trainingSet:
var trained = ee.Classifier.smileCart().train({
features: trainingSet,
classProperty: 'class',
inputProperties: predictionBands
}); Classify the testingSet and get a confusion matrix. Note that the classifier automatically adds a property called ‘classification’, which is compared to the ‘class’ property added when you imported your polygons:
var confusionMatrix = ee.ConfusionMatrix(testingSet.classify(trained)
.errorMatrix({actual: 'class',
predicted: 'classification'})); Print the confusion matrix and expand the object to inspect the matrix. The entries represent the number of pixels. Items on the diagonal represent correct classification. Items off the diagonal are misclassifications, where the class in row i is classified as column j. It’s also possible to get basic descriptive statistics from the confusion matrix. For example:
print('Confusion matrix:', confusionMatrix);
print('Overall Accuracy:', confusionMatrix.accuracy());
print('Producers Accuracy:', confusionMatrix.producersAccuracy());
print('Consumers Accuracy:', confusionMatrix.consumersAccuracy()); Note that you can test different classifiers by replacing CART with some other classifier of interest. Also note that as a result of the randomness in the partition, you may get different results from different runs.
4.5 Hyperparameter Tuning
Another fancy classifier is called a random forest (Breiman 2001). A random forest is a collection of random trees in that the predictions of which are used to compute an average (regression) or vote on a label (classification). Their adaptability makes them one of the most effective classification models, and is an excellent starting point. Because random forests are so good, we need to make things a little harder for it to be interesting. Do that by adding noise to the training data:
var sample = landsat.select(predictionBands).sampleRegions(
{collection: trainingFeatures
.map(function(f) {
return f.buffer(300)
}
), properties: ['class'], scale: 30});
var classifier = ee.Classifier.smileRandomForest(10)
.train({features: sample,
classProperty: 'class',
inputProperties: predictionBands
});
var classified = landsat.select(predictionBands).classify(classifier); Map.addLayer(classified, {min: 0, max: 2, palette:
['red', 'green', 'blue']}, 'classified') Note that the only parameter to the classifier is the number of trees (10). How many trees should you use? Making that choice is best done by hyperparameter tuning. For example,
var sample = sample.randomColumn();
var train = sample.filter(ee.Filter.lt('random', 0.6));
var test = sample.filter(ee.Filter.gte('random', 0.6));
var numTrees = ee.List.sequence(5, 50, 5);
var accuracies = numTrees.map(function(t) {
var classifier = ee.Classifier.smileRandomForest(t)
.train({
features: train,
classProperty: 'class',
inputProperties: predictionBands
});
return test.classify(classifier)
.errorMatrix('class', 'classification')
.accuracy();
});
print(ui.Chart.array.values({
array: ee.Array(accuracies),
axis: 0,
xLabels: numTrees
})); You should see something like the following chart, in which the number of trees is on the x-axis and estimated accuracy is on the y-axis:
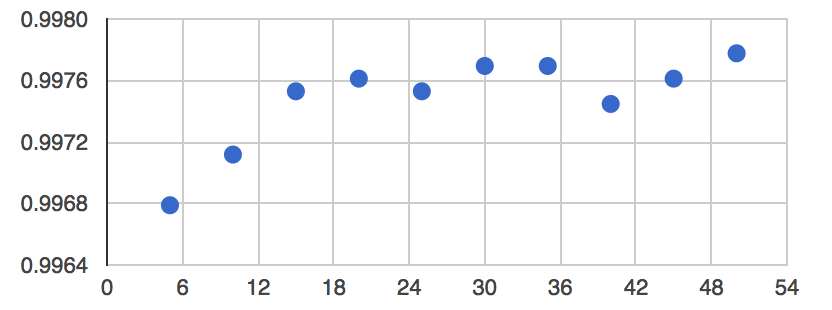
Chart, scatter chart Description automatically generated
First, note that we always get very good accuracy in this simple example. Second, note that 10 is not the optimal number of trees, but after adding more (up to about 20 or 30), we don’t get much more accuracy for the increased computational burden. So 20 trees is probably a good number to use in the context of this example.
4.6 Assignment
Design a four-class classification for your area of interest. Decide on suitable input data and manually collect training points (or polygons) if necessary. Tune a random forest classifier. In your code, have a variable called trees that sets the optimal number of trees according to your hyper-parameter tuning. Have a variable called maxAccuracy that stores the estimated accuracy for the optimal number of trees.
Where to submit
Submit your responses to these questions on Gradescope by 10am on Wednesday, September 30. If needed, the access code for our course is 6PEW3W.